A Lab for Machine Learning in Finance
By Jacques Joubert & Ashutosh Singh

Abstract
In the summer of 2018 we attended a conference organized by Quantopian in which we heard Dr. Marcos Lopez de Prado outline the challenges of building successful quantitative investment platforms using machine learning. His book, Advances in Financial Machine Learning provides solutions to many of the problems faced by the quantitative finance community. We, however, could not find a cogent implementation of these ideas in the public domain. We considered this to be an opportunity to build an all rights reserved package in Python (a language that has gained considerable following) which implements the concepts presented in the book while using good software engineering techniques. We aspire to make this a research platform where we along with contributors from the community add tools, techniques, algorithms, and research papers to the benefit of all quantitative practitioners applying machine learning in finance.
We have made good progress and the results and response from the community is very encouraging. In days and months to come we expect to add more functionality to this package.
Introduction
In recent years Python has been attracting a lot of attention for being the go to language for data science and machine learning. Many large organizations have contributed to this movement by making their in-house tools available on platforms like Github. For example, Google’s Tensorflow, Facebook’s PyTorch, and AQR’s pandas.
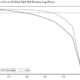
Prior to the release of Tensorflow in November 2015, there was a constant debate between which language was better – Python or R. In the plot below, generated using Google Trends, you can see how Python has become the language of choice. This is due to the release of new packages with widespread adoption coupled with Python’s ability to produce high-quality production-ready code.

Google Trends
“The Y axis represent search interest relative to the highest point on the chart for the given region and time. A value of 100 is the peak popularity for the term. A value of 50 means that the term is half as popular. A score of 0 means there was not enough data for this term.” (Google 2019)
In 2018, Wiley published a first of its kind textbook on financial machine learning titled “Advances in Financial Machine Learning” by Marcos Lopez de Prado. This book quickly became an important source of foundational ideas, concepts and principles underlying the use of machine learning in finance. Although a year later, the techniques outlined in the book had become popular, there was no available implementation of the ideas. It was for this reason that we saw the opportunity to code up a well-designed package based on agile project management and modern day software engineering tools.
The motivation for the package was to contribute to the quantitative finance community as well as to help speed up the learning process for students. Overall the goal of this package is to reduce implementation friction, fast track learning, and to help bridge the gap between theory and practice. Typically research of a quantitative strategy is a process that entails reading an academic paper, coding up an implementation, trying it on proprietary data, and then analyzing the results. This package would speed up this entire process by allowing users to jump directly to applying the methodology to their data.
The package also benefits institutions teaching post graduate courses in financial machine learning. We have provided two years of free sample data based on the new data structures along with a tested and well documented code base, allowing students to more easily build an intuition behind the techniques and play around with real data. We have additionally expanded on a few concepts to help answer questions that we struggled with, such as Meta-Labeling where we provide a toy example and results using a finance setting.
The rest of the paper is structured as follows: Section 2 reviews 6 of the 10 reasons why most machine learning funds fail and explains the package’s solutions. Section 3 discusses the paradigm shift from Lopez de Prado’s work relative to traditional methods such as factor investing and Section 4 elaborates by explaining how these concepts can be translated across strategies. Section 5 takes a high level overview regarding the package design, the tools we used, and the project management style we followed. Section 6 describes how we built a community around the package and section 7 provides some tutorials to help readers get started. Section 8 highlights the vision for the project going forward and a thank you note to WorldQuant University.
Paradigm Shift
Lopez de Prado’s book provides us with a very different way of building investment strategies. Rather providing readers with alpha generation techniques, the book provides a framework which can be leveraged to produce robust investment strategies.
The techniques he proposes are rather different when compared to the style of factor-based investing from Grinold and Kahn 2000 or Chincarini and Kim 2006.
- A lot of focus is spent on enhancing features and sampling techniques to boost statistical properties. The exciting thing is that those techniques could be applied to factor-based portfolios and the hope is that they would perform even better (perhaps a good future paper would be able to test this empirically).
- Practitioners have long known that the covariance structure between various assets is an important feature for forecasting risk as well as returns. This often leads to a model which follows a many-to-many architecture such as a vector autoregression (VAR) model, Lopez de Prado however, makes use of a many-to-one structure. He proposes modeling one asset at a time, which is enforced by making use of the volume clock sampling techniques and its derivatives.
- Lopez de Prado also takes more of a trading approach rather than an investing one, which makes a lot of sense in the context of machine learning. A good example is how structural breaks are used to set-up trades. These trades are then modeled using machine learning and the position sizes are determined using meta-labeling in combination with bet sizing algorithms.
- At first glance, readers may assume that Lopez de Prado suggests using features derived from only price action such as market microstructure features and structural breaks but that is only because he elaborated on those chapters. Our understanding is that the models discussed in his work can take a wide range of features, from traditional accounting ratios and macroeconomic data to satellite imagery and features compressed using dimensionality reduction techniques.
- Another key contribution from his work is stressing the importance of keeping count of the number of trials you run in order to avoid a false discovery. He proposes a Deflated Sharpe ratio and is vocal about the implications of running backtests in an iterative process. Rather he suggests using metrics such as feature importance and correct cross-validation techniques which are finance specific.
A paper by researchers at AQR Capital offers a solution much closer to the paradigm of factor investing. It is “Empirical Asset Pricing via Machine Learning” Gu, Kelly, and Xiu 2018.
Use of Techniques Across Strategies
Three ideas that stand out to us from the hoard of great ideas in the textbook are meta-labeling, data preparation, and feature engineering. These concepts are implemented into the mlfinlab package and are readily available.
We would like to give special attention to Meta-Labeling as it has solved several problems faced with strategies:
- It increases your F1 score thus improving your overall model and strategy performance statistics. It also leads to shorter drawdown periods when compared to strategies with a higher precision and a lower F1 score.
- It solves the problem of needing to use online algorithms due to the non-stationary nature of financial markets. A typical example is to train a model on 70% and then test it on 30% of the data. Given this model has favourable performance metrics, it would stop working when a structural break occurs. A toy example is to consider a trending strategy. When the market stops trending, the strategy will likely lose money. Meta-Labeling avoids this by identifying market regimes/states in which the primary model will perform poorly. It helps to filter out the false positives.
- It allows us to determine optimal position sizes by weighting the trades based on the model confidences. Thus positions with high uncertainty receive less money.
Package Design
The following section outlines the design principles and tools that we made use of in the creation of mlfinlab. We also provide a brief explanation of the package structure.
Lean Startup Principles
The Lean Startup is a book written by Ries, Eric. 2011 which outlines the process of running a startup company based on validated learning and a build-measure-learn feedback loop.
The key idea is to set up a cycle of ideation, building a minimum viable product (MVP), releasing to market to measure various performance metrics, and learning from the data.
An example of we did this was:
- Came up with the idea that a python package based on Advances in Financial Machine Learning would be useful.
- Coded up a very small MVP giving users the ability to create the various data structures.
- Released it to early adopters.
- Measured the feedback in terms of Github stars, Reddit votes, and Twitter retweets.
- Identified which groups of people wanted the product so we could target them in the future and listened to which parts of the literature they wanted us to develop next.
Overall this process has yielded great results by making sure that we build implementations which are in demand, it also had the added benefit of building a following as we developed the product.
Below are some of the metrics we are using to measure the product/market fit:
- PyPi package downloads
- Github Stars and the number of unique clones
- Reddit comments and votes
- Twitter retweets and likes
Interestingly the two countries with the highest number of downloads are the United States of America and China.
Continuous Integration
Continuous Integration (CI) is a software engineering practice where developers push their iterative changes to the code base to a central and shared repository, where a build server runs automatic scripts to check for best practices such as code style checks, 100% code coverage, and unit tests passing are enforced. These checks allow the team to detect problems early on and provide guidelines for writing production-ready code.
We make use of the following tools:
- Github for version control and repositories
- Travis as a CI tool and automatic build server
- GitKracken as a version control GUI
- Bash scripts to execute checks
- Pylinter to enforce code coverage
- Test-driven development with 100% code coverage
Package Structure
We try to follow the principles of Object Oriented programming (OOP) as close as possible.
The package in its current form has the following useful directories:
- Data structures: Code relating to the creation of various standard and information-driven bars.
- Filters: Specific event filters used to place trades. An example is the CUSUM filters used to determine structural breaks.
- Features: Tools for creating useful features for machine learning algorithms, such as fractional differentiation and entropy features.
- Labeling: Containing the logic for labeling financial data, such as the Triple Barrier technique and Meta-Labeling.
- Utils: Shared code throughout the code base, such as the multiprocessing engine.
- Tests: Containing all the unit tests which can be locally run to ensure that the package works on your local python environment.
Building a Community
Finding users for the package, welcoming them, getting them excited about contributing to your project, providing support and structure in a virtual team, hosting meetup events to evangelize the package, and creating community guidelines are all a part of running a successful open source project. The following section outlines some of steps we have taken in setting up our own community.
Creating an Organisation
Building on the ideas of Lopez de Prado (Lopez de Prado 2018b) and pulling inspiration from AQR (Applied Quantitative Research) we decided to setup a brand called Hudson and Thames Quantitative Research, based on the rivers where the authors reside. It would be the platform for a finance research laboratory where anyone could contribute to the development of tools.
![]()
Setting up such an organization would allow us to leverage the project in various ways. For example, we could now launch a crowdfunding campaign to fund the development of mlfinlab or pivot to a consultancy/asset management business.
By doing this we can build a product, a brand, and a client base – before the product has reached its final form.
Github Guidelines
Github acts as a platform to develop software and is well known as a repository for projects such as Numpy, Pandas, Scikit Learn, and Tensorflow.
They also provide a number of guidelines (Github 2019) for running a project. In particular, they recommend the following documents which have been included in the mlfinlab repository.
- ReadMe: Introduces and explains a project.
- Code of conduct: A welcoming and inclusive document that outlines the community standards and outlines procedures for abuse.
- Contributing Guidelines: Outlines how members of the community can participate in the project and the types of desired contributions.
- License: All rights reserved and private.
- Issue & pull request templates: Templates are provided to help contributors include information in a commit that would be relevant. For example the bug they fixed, which operating system and IDE they used.
Online Community Channels
A project of this nature is very niche and thus we expect the community to be very small. In essence, we are targeting users that use python, are familiar with machine learning, and care about finance. It is even smaller when we subset it to those users that are actively reading academic literature and exploring modern techniques.
The following are the online sources that we made use of to reach users:
We had by far the most success with Reddit. Due to the subreddit structure, we are able to reach groups of people that subscribe to specific subreddits. Overall we found that technology-focused groups were very vocal and pro the package where the more fundamental/discretionary investor communities disliked it.
Our conclusion is that it would be much harder to sell the idea of machine learning to companies that weren’t already aligned with systematic investing. Thus when considering the idea of consulting or selling a machine learning product, avoid firms that are focused on fundamental style strategies, and focus on companies that were already exploring the idea.
We received a high number of votes in both the algorithmic trading and machine learning communities, as shown in the figure below.

Reddit Feedback
Twitter has been great for instant responses from noteworthy persons and building somewhat of a brand name and reputation. In particular, Lopez de Prado has retweeted our research as well as liked several of our tweets regarding the package.
Blog: Quantsportal.com
Jacques’ personal blog has been around since 2015 and has built a small following in the quantitative finance community. It has acted as a portfolio of his work since his undergraduate days and we made use of its distribution channels to get the message out regarding package developments. In particular, the blog is linked to the well-known blog aggregator Quantocracy.com.
LinkedIn and Facebook
Overall the feedback from Linkedin and Facebook was disappointing. The message reaches our personal network with a few conversations starting but we didn’t feel that the message carried beyond our network.
Offline Community Channels
Typically offline events refer to meetups and guest speaking opportunities in which you promote the package.
Guest Speaking
We have made use of the Meetup.com website and created a Machine Learning in Finance London group which at the time of writing has 250 members. Our first meetup is scheduled for the 23 May 2019 at Monticello House. We will also be guest speaking at the London Python for Trading Meetup on the 22nd of May 2019.

Machine Learning in Finance London
Sponsorship
Thankfully we have secured sponsorship from GridGain Systems, a high-performance computing company who also hosts the In-Memory Computing Summit, which includes tickets for our members to events, fees covered for venue hire, and possible speakers on the topic of machine learning to host at our meetup.
Tutorials
We are in the process of creating a few tutorial notebooks which we will use at our meetup events in London. They can be found along with the other example notebooks on the Research Repository.
At the time of writing we have the following example notebooks:
- Analysis of statistical properties for the various standard bars
- Analysis of Imbalance bars
- Stitching together futures contracts using the ETF trick
- A toy example of Meta-Labeling using MNIST data
- An end to end trend following strategy showcasing the benefits of Meta-Labeling
- An end to end mean-reverting strategy showcasing the benefits of Meta-Labeling
- Using Fractionally Differentiated Features
There is another developer which runs the BlackArbsCEO repository on GitHub which has notebooks covering multiple chapters. We recommend readers also view his work.
Final Remarks
Mlfinlab as a package will be in a constant state of development. Our vision is to implement all of the principals mentioned in the textbook and then move onto adding other recent developments in financial machine learning, as they emerge.
The success of the project will be based on user adoption of these techniques and if we can generate a source of revenue to justify the many hours spent developing it.
At the time of writing, we are a team 5 individuals all in different locations, implementing the various chapters. For some of us, this project is a platform to help us get placement at top employers, for others it a tool to help build a reputation in the industry.
References
[CK06] Ludwig. B. Chincarini and Daehwan. Kim. Quantitative Equity Portfolio Management. McGraw Hill, 2006.
[ELO12a] David Easley, Marcos M. López De Prado, and Maureen O’Hara. “Flow toxicity and liquidity in a high-frequency world”. In: Review of Financial Studies 25.5 (2012), pp. 1457–1493.
[ELO12b] David Easley, Marcos M. López De Prado, and Maureen O’Hara. “The Volume Clock: Insights into the High-Frequency Paradigm”. In: Journal of Portfolio Management 39 (2012), pp. 19–29.
[FB66] Eugene F. Fama and Marshall E. Blume. “Filter rules and stock-market trading”. In: Journal of Business 39.1 (1966), pp. 226–241.
[Git19] Github. Github Open Source Guides. [Online; accessed May 11, 2019].
2019. url: https://opensource.guide/.
[GK00] Richard. C. Grinold and Ronald. N. Kahn. Active Portfolio Management. McGraw Hill, 2000.
[GKX18] Shihao Gu, Bryan T. Kelly, and Dacheng Xiu. “Empirical Asset Pricing via Machine Learning”. In: National Bureau of Economic Research w25398 (2018), pp. 1–68.
[Goo19] Google. Machine Learning Trends. [Online; accessed May 11, 2019]. 2019. url: https : / / trends . google . com / trends / explore ?date = all & q = Python % 20Machine % 20Learning , R % 20Machine %20Learning.
[Hos81] J. R. M. Hosking. “Fractional Differencing”. In: Journal of Portfolio Management 68.1 (1981), pp. 165–176.
[Lop15] Marcos. Lopez de Prado. “Quantitative Meta-Strategies. Practical Applications.” In: SSRN (2015), pp. 1–6.
[Lop18a] Marcos. Lopez de Prado. “Market Microstructure in the Age of Machine Learning”. In: (2018), pp. 1–48.
[Lop18b] Marcos Lopez de Prado. “The 10 Reasons Most Machine Learning Funds Fail”. In: Ssrn (2018). issn: 1556-5068. doi: 10.2139/ssrn.3104816.
[Lop18c] Marcos. Lopez de Prado. “The 10 Reasons Most Machine Learning Funds Fail”. In: Journal of Portfolio Management 44.6 (2018), pp. 120–133.
[Rie11] Ries, Eric. The lean startup: How today’s entrepreneurs use continuous innovation to create radically successful businesses. Crown Books, 2011.
[TH00] Ané Thierry and Geman Hélyette. “Order Flow, Transaction Clock, and Normality of Asset Returns”. In: 55.5 (2000), pp. 2259–2284.
[Wik19] Wikipedia, the free encyclopedia. Precision and recall. [Online; accessed March 18, 2019]. 2019. url: https://en.wikipedia.org/wiki/Pr